Dass künstliche Intelligenz (KI oder AI) ein enormes Potenzial für die Medizin birgt, haben viele Hersteller bereits erkannt. Was aber, wenn die Schlüsse der KI für den Menschen nicht mehr nachvollziehbar sind? Ein reales und akutes Problem, bei dem das Konzept der “Interpretierbarkeit von KI” hilft.
Die Interpretierbarkeit von maschinellem Lernen sorgt dafür, dass KI-basierte (Medizin-)Produkte nicht zur Blackbox werden. Sie erlaubt es, Fehler zu identifizieren und Sicherheitslücken zu vermeiden.
Erfahren Sie in diesem Beitrag,
- was Interpretierbarkeit von maschinellem Lernen bedeutet,
- welche Probleme sie löst und
- welche Methoden es hierfür gibt.
Kapitel 1 und 2 geben eine allgemein verständliche Einführung in das Thema. Kapitel 3 und 4 behandeln spezielle Methoden, mit denen die Interpretierbarkeit von Machine-Learning-Modellen erreicht werden kann.
1. Was bedeutet Interpretierbarkeit im maschinellen Lernen?
a) Maschinelles Lernen
Maschinelles Lernen (ML) ist ein Teilgebiet der künstlichen Intelligenz (KI). Es ermöglicht dem Computer, aus Daten Regeln zu “lernen”, ohne explizit programmiert werden zu müssen. In der Medizintechnik kommt maschinelles Lernen vor allem bei der Verarbeitung von Bild- und Textdaten zum Einsatz. Dabei wird häufig auf sogenanntes “Deep Learning” zurückgegriffen. Deep Learning bezeichnet künstliche neuronale Netze, die besonders viele “Schichten” haben.
Mehr über die Grundlagen der künstlichen Intelligenz bzw. des maschinellen Lernens erfahren Sie im Artikel zu Künstlicher Intelligenz in der Medizin.
b) Interpretierbarkeit von maschinellem Lernen
Was ist mit Interpretierbarkeit von maschinellem Lernen gemeint?
Der Grad, bis zu dem ein System Klarheit über die Gründe für die Ergebnisse (die Outputs) verschaffen kann
Beispiel: Ein Verfahren, das die Relevanz der Features eines Machine-Learning-Modells bewertet, kann die Erklärbarkeit des Modells erhöhen.
Der Grad, bis zu dem ein System Informationen über sein Innenleben, also seine innere Struktur und Trainingsdaten, offenbart
Erläuterung: Damit ist Transparenz nicht dasselbe wie Erklärbarkeit. Transparenz setzt das Öffnen der Blackbox voraus, Erklärbarkeit nicht. Ein einfacher Entscheidungsbaum hat zum Beispiel eine hohe Transparenz, da man die Vorhersage dieses Modells direkt aus der Struktur des Baums ablesen kann.
Der Grad, bis zu dem jemand die Information nutzen kann, die das System durch Erklärbarkeit und Transparenz liefert
Nach dieser Definition lässt sich also eine Gleichung aufstellen:
Interpretierbarkeit = Erklärbarkeit + Transparenz
Es gibt daher zwei Stellschrauben, um die Interpretierbarkeit im maschinellen Lernen zu verbessern: die Erklärbarkeit und die Transparenz.
Transparenz lässt sich durch den Einsatz von inhärent transparenten Modellen oder Methoden erzeugen, die nach dem Trainieren der KI angewandt werden.
Erklärbarkeit wird unterstützt durch viele verschiedene Ansätze für unterschiedliche Datentypen und Fragestellungen. Dieser Artikel stellt beide Konzepte vor.
c) Warum sind Modelle im maschinellen Lernen so schwer nachzuvollziehen?
KI-Entscheidungsmechanismen hängen von Mustern in Daten ab. Zum einen lernt die KI solche Muster, um menschliche Fähigkeiten nachzuahmen (beispielsweise, Objekte in Bildern zu erkennen). Zum anderen kann eine KI aber auch Muster erkennen, die dem Menschen verborgen bleiben.
Die Modelle, die sich aus diesem Prozess des maschinellen Lernens ergeben, sind kaum noch nachvollziehbar. Dies liegt vor allem daran, dass das System diese Modelle durch die Daten, mit denen es lernt, selbst erstellt. Das Ergebnis dieses “Lernprozesses” ist nicht mehr durch einen Menschen programmiert.
Zudem sind die Modelle äußerst komplex. In neuronalen Netzwerken werden beispielsweise Millionen von Parametern trainiert. Deshalb sind KI-Modelle in vielen Fällen eine Blackbox und selbst für diejenigen nicht nachvollziehbar, die sie entwickelt haben.
2. Probleme vermeiden durch Interpretierbarkeit von KI
So leistungsfähig KI auch sein kann: Fehlende Transparenz und Erklärbarkeit können dazu führen, dass schwere Fehler unerkannt bleiben oder dass das Modell unbrauchbar wird. Schlimmstenfalls werden dadurch Patienten gefährdet.
a) Beispiele
Wie gefährlich ein Mangel an Interpretierbarkeit für Patienten werden kann, lässt sich am besten anhand von Beispielen illustrieren:
Gefahren durch intransparente Modelle
Intransparenz kann dazu führen, dass dem Hersteller Fehlschlüsse der KI nicht rechtzeitig auffallen. Beispiel: Ein KI-Modell erkennt Krebs nicht zuverlässig anhand eines verdächtigen Lungengewebes, sondern (auch) daran, dass die Aufnahmen von einer bestimmten Person wie einem Onkologen beauftragt wurde.
Gefahren durch nicht erklärbare Modelle
Sepsis Watch ist ein Modell, das auf Grundlage von klinischen Daten Sepsis bei stationär aufgenommenen Patienten vorhersagt. Das Modell wurde in den klinischen Alltag integriert. Für die Benutzung des Tools war eine Rapid Response Team (RRT) Nurse zuständig. Bei einer Warnung durch das Programm verständigt die RRT Nurse die Ärzte auf der jeweiligen Station. Das Verfahren beruhte auf Deep Learning und lieferte keine Erklärung für die Sepsiswarnung. Dies führte zu erhöhtem Aufwand in der Kommunikation (“Aber der Patient hier sieht fit aus, warum soll er ein hohes Risiko haben?”, fragten die Ärzte) und dazu, dass RRT Nurses sich irgendwie zusammengereimt haben, woher gerade diese Vorhersage kam. Die Nutzerinnen und Nutzer haben sich also eine “Interpretierbarkeit” geschaffen, die jedoch häufig unzutreffend war.
(Referenz: Repairing Innovation – A Study of Integrating AI in Clinical Care)
b) Wie Interpretierbarkeit Probleme löst und Gefahren minimiert
Um mögliche Probleme zu vermeiden und Gefahren zu minimieren, sollten Entwickler die Interpretierbarkeit von KI-Systemen gewährleisten. Dazu müssen sie:
Fehler während der Entwicklung finden
Nicht alle Fehler haben ihre Ursache in einer niedrigen Güte des Modells. Manche Fehler entstehen z. B. durch bereits in den Daten vorhandene nicht-kausale Korrelationen und lassen sich mithilfe der Interpretierbarkeit aufdecken.
- Nicht direkt kausale Faktoren: Wenn Asthma fälschlicherweise als mildernder Faktor für Lungenentzündung genutzt wird, obwohl der eigentliche Kausalzusammenhang ist, dass Asthmapatienten schneller Antibiotika verschrieben bekommen, da sie eine Risikogruppe sind. Daher sinkt für sie insgesamt das Risiko, an einer Lungenentzündung zu erkranken. Mehr Infos dazu gibt es in diesem Paper.)
- Verzerrte Ergebnisse: Eine KI, die automatisch einer bestimmten Ethnie eine mangelnde Kreditwürdigkeit zuordnet, da sie durch initiale Fehlprogrammierung gelernt hat, dass Minderheiten schlechtere Einkommen haben.
Limitationen des Modells entdecken
Die Interpretierbarkeit eröffnet die Möglichkeit, sich gezielt mit den Wirkmechanismen des Modells auseinanderzusetzen. Stellt man beispielsweise fest, dass sich ein Diagnosetool vor allem auf den Text aus Arztbriefen stützt und weniger auf Blutwerte, Visitendaten usw., funktioniert das Modell wahrscheinlich schlechter in Kliniken, in denen der Arztbrief nur analog vorliegt und dem System nicht zur Verfügung steht.
Sicherheitslücken identifizieren
Manche Risiken lassen sich nur mithilfe der Interpretierbarkeit bewerten. Adversarial Attacks (Angriff, bei dem die KI durch eine manipulierte Eingabe zu Fehlverhalten verleitet wird) können aufzeigen, ob das Modell angreifbar ist.
Vertrauen bei allen Stakeholdern schaffen
Mithilfe der Interpretierbarkeit kann man die Wirkungsweise des Modells mit Expertenwissen abgleichen, um so ein gewisses Vertrauen aufzubauen.
Feedback erhalten, um das Modell zu verbessern
Das gilt vor allem für die Entwickler des Modells: Zeigt sich, dass sich das Modell auf bestimmte Features verlässt, so kann man diese gezielt durch Feature Engineering (also Erzeugung neuer, abgewandelter Features) verbessern. Beispiel: Wenn ein bestimmter Blutwert ein wichtiges Feature ist, lässt sich möglicherweise die Vorhersage verbessern, wenn die Entwicklung dieses Blutwerts über die Zeit als Feature verwendet wird.
Belege für die Leistungsfähigkeit und Sicherheit erhalten
Sind die Systeme verständlicher, lässt sich auch die Sicherheit und Leistungsfähigkeit der Produkte besser nachweisen. Diese Nachweise sind z. B. für Benannte Stellen wichtig.
Christoph Molnar spricht mit Professor Johner über die Interpretierbarkeit von Machine Learning, über typische Fehler dabei und Lösungsansätze. Sie besprechen dabei auch die Literatur.
Diese und weitere Podcast-Episoden finden Sie auch hier.

3. Interpretierbarkeit durch Transparenz schaffen
Interpretierbarkeit kann durch Transparenz erreicht werden. Hier wiederum gibt es grundsätzlich zwei Möglichkeiten:
- Transparenz per Design
Hierbei geht es um die Nutzung von inhärent transparenten Modellen. Man kann sich von vornherein auf Modelle beschränken, die eine leicht verständliche und somit transparente Struktur haben, z. B. Entscheidungsbäume und Generalized Additive Models.
- Nachträgliche Transparenz
Hierbei wird bei eigentlich intransparenten Modellen nachträglich Transparenz erzeugt durch spezielle Methoden. Diese machen komplexe Modelle wie neuronale Netze interpretierbar, indem sie ihre Struktur transparenter machen.
a) Transparenz per Design
Generalized Additive Models
Der Name klingt sehr kompliziert, aber letztendlich sind Generalized Additive Models (GAM) mathematische Formeln, die die Vorhersage aufgrund der Features berechnen. Diese Formeln gewichten und kombinieren die Features, wobei der optimale Wert der Gewichte im Trainingsprozess gelernt wird. Ein GAM ist ein transparentes Modell, da man direkt aus den Formeln ablesen kann, wie die Vorhersage gemacht wird.
Beispiel GFR-Score
Die glomeruläre Filtrationsrate (GFR) ist eine wichtige Kennzahl für die Nierenfunktion (je niedriger, desto schlechter die Nierenfunktion). Die GFR ist aber schwer zu messen. Diese Kennzahl wird mithilfe von Features geschätzt und nennt sich dann eGFR. Es gibt verschiedene Formeln dafür, z. B. die MDRD-Formel:
eGFR = 175 x SKr -1,154 x A -0,203
Dabei steht SKr für das Serumkreatinin und A für das Alter der Patienten. Zusätzlich wird der Score bei Frauen mit 0,742 multipliziert und bei Personen mit schwarzer Hautfarbe mit 1,212 (ein Faktor, für den es bereits harsche Kritik gab). Der genaue Wert für diese Gewichtung haben Forscher mithilfe von Daten geschätzt.
Ein paar Mathekenntnisse vorausgesetzt, kann man direkt aus dieser Formel ablesen, dass eine Erhöhung des Alters (bei gleichbleibenden anderen Faktoren) zu einem niedrigeren eGFR-Score führt.
Weitere Beispiele von inhärent interpretierbaren Modellen
- Entscheidungsbäume: Beim maschinellen Lernen werden diese nicht per Hand konstruiert, sondern die “Verästelungen” werden aus den Daten gelernt. Aber: So eine Whitebox wird schnell auch zur Blackbox. Ein sehr tiefer Entscheidungsbaum ist nur schwer nachvollziehbar.
- Eng verwandt mit Entscheidungsbäumen sind Entscheidungsregeln. Eine Entscheidungsregel folgt immer dem typischen if-then-Konstrukt: Wenn bestimmte Feature-Werte vorliegen, wird eine bestimmte Vorhersage getroffen.
b) Nachträgliche Transparenz
Beispiele von Modellen, die nicht inhärent interpretierbar sind
- Ein klassisches Beispiel sind tiefe neuronale Netze (Stichwort: Deep Learning). Diese sind in der Regel nicht nachvollziehbar und fallen daher in die Kategorie der Blackbox-Modelle.
- Ein weiteres Beispiel ist der Random Forest. Wie der Name verrät, besteht der Random Forest aus Bäumen, also Entscheidungsbäumen. Diese gelten eigentlich als transparent. Aber dadurch, dass der Random Forest aus mehreren hundert Bäumen besteht, muss man auch diesen als Blackbox-Modell kategorisieren – die Transparenz geht durch die Komplexität verloren.
Methoden für mehr Transparenz
Auch für Blackbox-Modelle kann man die Transparenz erhöhen. Das erfordert zusätzlichen Aufwand, um einzelne Komponenten eines Modells zu interpretieren, z. B. einzelne Neuronen in einem neuronalen Netzwerk.
Beispiel Feature-Visualization-Methode
Die Feature-Visualization-Methode ist ein gutes Beispiel für die Erhöhung der Transparenz in Convolutional Neural Networks (CNN). CNNs werden zur Klassifikation von Bildern eingesetzt. Welche Rolle hierbei einzelne Neuronen spielen, ist erst einmal nicht ersichtlich. Das CNN ist nicht transparent.
Mithilfe der Feature-Visualization-Methode lassen sich gezielt Bilder erzeugen, auf die einzelne Neuronen im Netzwerk besonders ansprechen. Dadurch lässt sich besser interpretieren, wie das Modell funktioniert.
Abbildung 1 zeigt die Bilder, die verschiedene Neuronen des CNN aktivieren. Es zeigt sich, dass Neuronen auf den ersten Ebenen des Netzwerkes vor allem Kanten erkennen. Je tiefer die Ebene, desto komplexere Formen und Strukturen können erkannt werden, bis hin zu Objekten wie Hundeschnauzen.

Beispiel Attention Mechanismen
Ein weiteres Beispiel sind Attention Mechanismen von bestimmten neuronalen Netzwerken. Diese haben intern Gewichte, die bestimmen, wie stark bei einer Klassifikation oder Vorhersage z. B. auf bestimmte Bildregionen oder Wörter geachtet wird. Sie lassen sich visualisieren, um so die Transparenz für diese Netzwerke zu erhöhen. Es ist aber noch umstritten, wie sehr man diese Attention-Gewichte als Interpretation betrachten kann (mehr hierzu: Attention is not Explanation).
4. Interpretierbarkeit durch Erklärbarkeit
Ein anderer Ansatz, um die Interpretierbarkeit von KI zu gewährleisten, ist die Erklärbarkeit. Der große Vorteil gegenüber der Transparenz ist dabei, dass die Blackbox geschlossen bleiben kann. Erklärbarkeit arbeitet nur mit Inputs und Outputs und lässt das zugrunde liegende Modell unberührt.
a) Feature Effects
Ein Feature Effect beschreibt, wie sich ein einzelnes Feature (z. B. das Alter der Patienten) im Durchschnitt auf den Modelloutput (z. B. Krebsrisiko) auswirkt. Wichtig ist hier “im Durchschnitt”: Es geht nicht darum, wie sich das Feature in einem Einzelfall auswirkt, sondern darum, wie sich der Modelloutput für die Mehrzahl der Datensätze verhält.
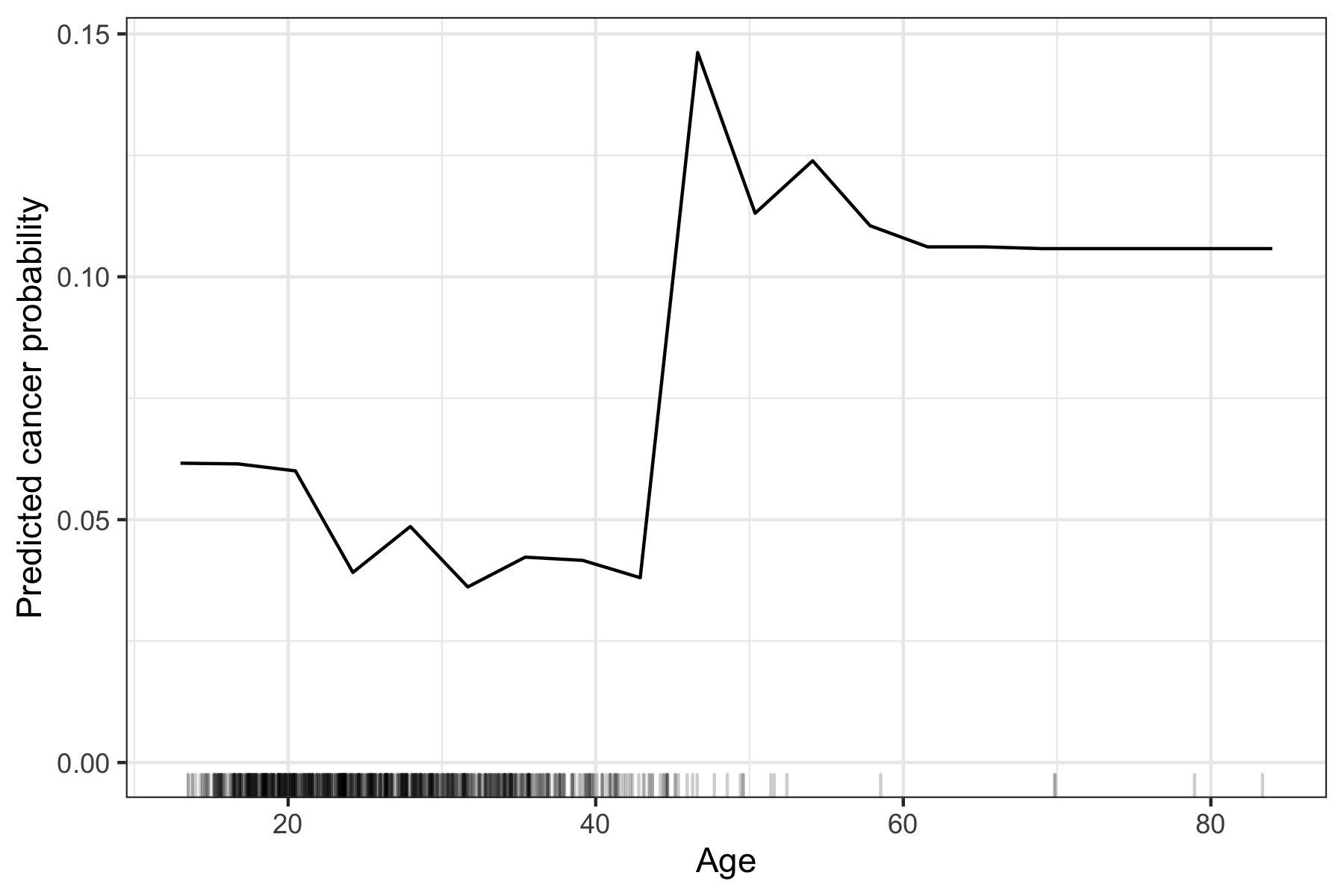
Feature Effects können mithilfe von Diagrammen visualisiert werden, auf denen man das Feature auf der horizontalen Achse vermerkt (hier Alter) und auf der vertikalen Achse die Vorhersage des Modells (hier Krebsrisiko).
Abbildung 2 zeigt ein Beispiel für einen Feature Effect Plot, der mit der Partial-Dependence-Plot-Methode erzeugt wurde. Für andere Methoden würde die Grafik sehr ähnlich aussehen. Man sieht, dass mit steigendem Alter die Krebswahrscheinlichkeit leicht sinkt. Um das vierzigste Lebensjahr steigt die Wahrscheinlichkeit, an Krebs zu erkranken, sprunghaft an, flacht danach wieder etwas ab und verharrt ab dem sechzigsten Lebensjahr auf konstant hohem Niveau. Die Striche auf der horizontalen Achse geben an, welches Alter man tatsächlich in den Daten beobachtet hat – fast niemand war älter als 50, daher sollte man auch den Feature Effect in diesem Bereich nicht überbewerten.
Berechnen des Feature Effects durch Partial Dependence Plot
Der Partial Dependence Plot wird auf folgende Art berechnet: Möchte man wissen, wie sich das Alter der Patienten durchschnittlich auf die vom Modell vorhergesagte Wahrscheinlichkeit für Krankheit X auswirkt, startet man mit dem geringsten Alter, das man in den Daten beobachtet (z. B. 20 Jahre). Dann setzt man künstlich alle Patienten in dem Datensatz auf das Alter 20 und misst die durchschnittliche Vorhersage für Krankheit für diesen Datensatz im Modell. Das Ganze wiederholt man für das Alter 21 usw., bis man bei 80 Jahren angekommen ist. Dadurch hat man simuliert, wie sich die Wahrscheinlichkeit ändert, wenn das Alter erhöht wird, aber die anderen Features der Patienten gleich bleiben.
Es gibt noch andere Techniken, um Feature Effects zu berechnen: Accumulated Local Effect Plots, Invididual Conditional Expectation Curves und Shapley Dependence Plots (aber das geht hier zu sehr in die Tiefe). Diese sind zum Teil komplizierter in der Berechnung als der hier beschriebene Partial Dependence Plot, aber funktionieren ähnlich und werden ähnlich interpretiert.
b) Permutation Feature Importance
Permutation Feature Importance ist eine Methode, die für die verschiedenen Input-Features eines Modells feststellt, wie wichtig diese für korrekte Vorhersagen der Daten waren.
Konzept
Die Permutation Feature Importance funktioniert nach einem einfachen Prinzip:
Zuerst wird die Performanz des Modells gemessen. Anschließend wird eines der Features permutiert, d. h. die Werte in der entsprechenden Tabellenspalte werden zufällig gemischt. Dadurch wir der Zusammenhang zwischen diesem Feature und der korrekten Vorhersage “zerstört”. Anschließend wird mit diesen “fehlerhaften” Daten noch einmal die Performanz des Modells gemessen. Diese ist entweder gleich geblieben, falls das Feature keinen Einfluss auf die Vorhersage hat, oder stark gefallen, falls das Modell sich für eine korrekte Vorhersage stark auf dieses Feature verlässt. Das Vorgehen wiederholt man für alle Features und erhält so ein Ranking der Wichtigkeit der einzelnen Features.
Die Beschreibung macht vielleicht schon deutlich, warum man auch diese Methode zur Erklärung von Blackbox-Modellen verwenden kann: Es geht darum, die Inputdaten des Modelles zu “manipulieren” und die Änderung der Ausgabe zu messen. Es wird keine Transparenz des Modells vorausgesetzt.
Beispiel
Vorhersagemodell über die Entwicklung von Bluthochdruck auf der Grundlage von kardiorespiratorischen Fitnessdaten
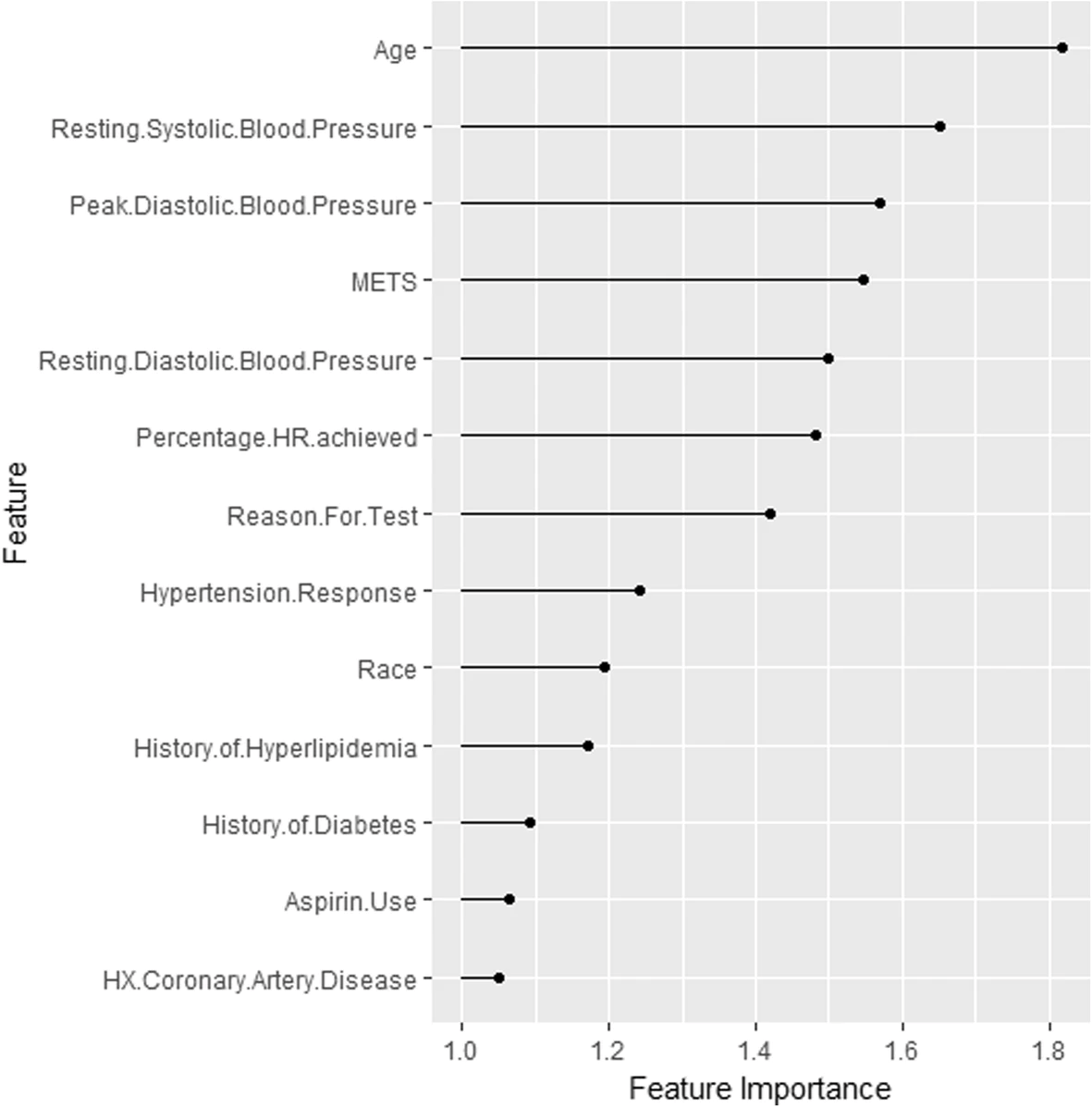
Hier sieht man z. B., dass das Alter das wichtigste Feature ist. Erst dann folgen Features wie systolischer Blutdruck in der Ruhe und maximaler diastolischer Blutdruck. Diese Informationen können jetzt mit Expertenwissen abgeglichen werden. Man weiß jetzt, dass das Alter ein wichtiger Faktor für das Modell ist, und es ist sinnvoll, die Modellperformanz in Abhängigkeit vom Alter zu betrachten.
c) Shapley Values
Die Erklärmethode Shapley Values eignet sich, um die Vorhersage für einzelne Datenpunkte zu erläutern. Hierbei wird die Vorhersage “fair” auf die einzelnen Features aufgeteilt, um zu erklären, wie die Vorhersagen des Modells zustande gekommen sind.
Konzept
Shapley Values kommen eigentlich aus der Spieltheorie: Man nimmt an, dass einige Spieler ein kooperatives Spiel spielen und ein Preisgeld erhalten. Wie soll dieses Preisgeld fair aufgeteilt werden? Die Shapley-Value-Methode bietet hier eine Lösung: Erst werden alle möglichen Kombinationen aus Spielern inklusive resultierendem Preisgeld simuliert. Dann wird für jede Konstellation verglichen: Wie hoch ist das Preisgeld mit oder ohne diesen Spieler? Die durchschnittliche Differenz im Preisgeld ist dann der faire Anteil für diesen Spieler.
Das Prinzip lässt sich auch auf Machine Learning übertragen: Die “Spieler” sind die einzelnen Featurewerte für einen bestimmten Datensatz. Das “Preisgeld” ist die Vorhersage des Modells, die es fair unter den Featurewerten aufzuteilen gilt. Es gibt noch eine Nuance zu beachten: Nicht die Vorhersage wird nicht komplett aufgeteilt, sondern die Differenz zur mittleren Vorhersage im gesamten Datensatz. Somit interpretiert man mit Shapley Values, warum genau dieser Datensatz eine andere Vorhersage hat als die Daten im Mittel haben.
Anwendungsgebiete
Shapley Values haben ein breites Einsatzgebiet: Neben Tabellendaten lassen sie sich auch für Bilddaten und Textdaten benutzen. Shapley Values können (zumindest bei Anwendung auf Tabellendaten) über Datensätze hinweg aggregiert werden. Somit erlauben sie Interpretationen über die gesamte Verteilung der Daten des Modells, z. B. hinsichtlich Feature Effects und Wichtigkeit der Features.
Beispiel
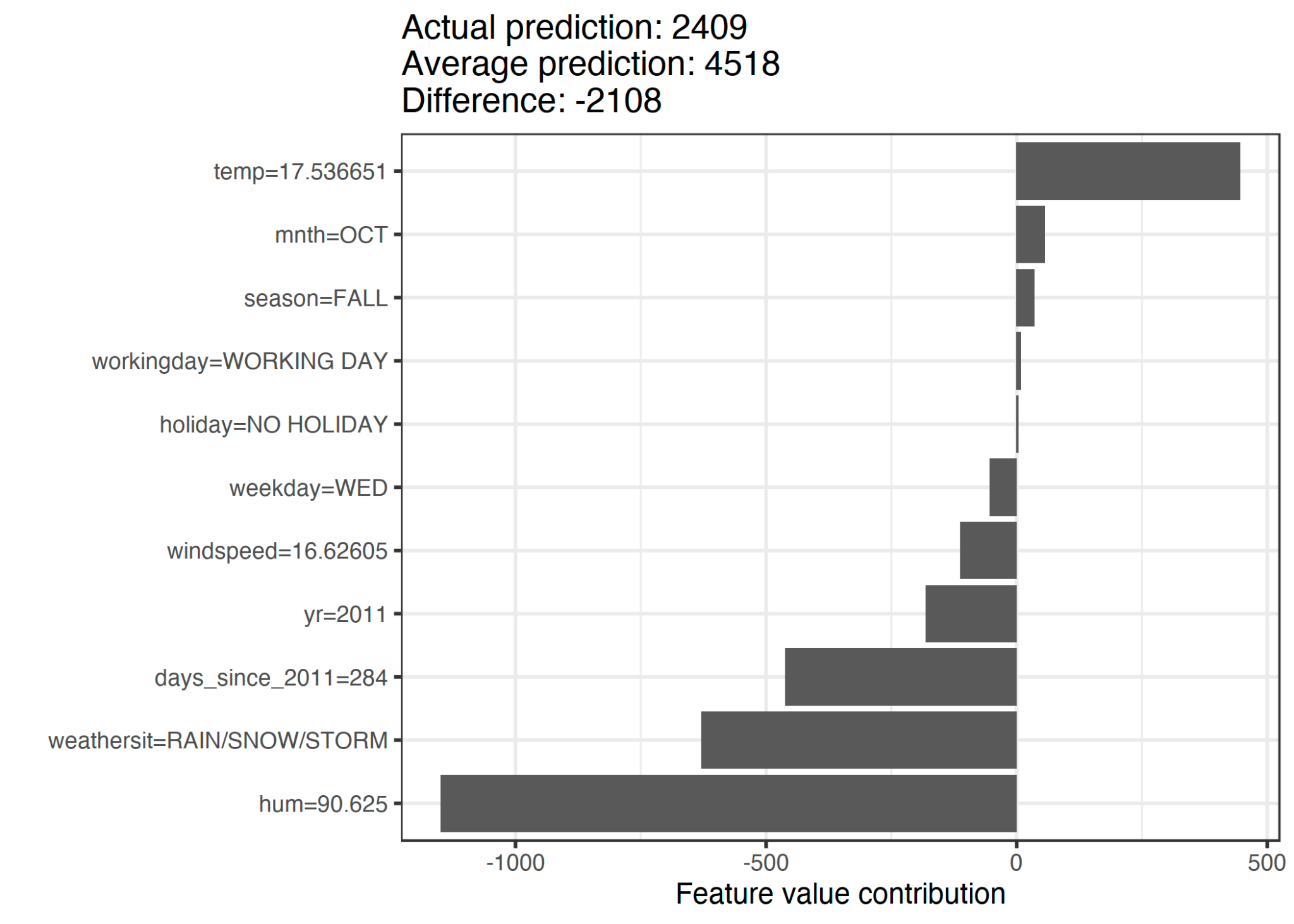
In folgendem Beispiel wurde ein Machine Learning Modell trainiert, das die Anzahl täglich ausgeliehener Fahrräder bei einem Fahrradverleih vorhersagt. Als Features wurden kalendarische Informationen wie Monat und Wochentag und Wetter benutzt. Ziel ist, die Vorhersage von 2.409 Fahrrädern für einen bestimmten Tag im Oktober, an dem es regnerisch war, zu erklären. Sie liegt um 2.108 Fahrräder unter der durchschnittlichen Vorhersage. Man sieht, dass vor allem die hohe Luftfeuchtigkeit von 90 % und das regnerische Wetter für diese niedrige Vorhersage verantwortlich waren (Abbildung 4). Es gibt aber mit der für Oktober milden Temperatur von 17 °C auch einen Faktor, der einen positiven Einfluss auf die Vorhersage hatte. Addiert man die Shapley Values für die Features, kommt man auf die Differenz von 2.108.
d) Counterfactual Explanations
Counterfactual Explanations sind “Was-wäre-wenn”-Erklärungen, die aufzeigen, welche Featurewerte geändert werden müssten, damit das Machine-Learning-Modell zu einer anderen Vorhersage käme. Ähnlich wie Shapley Values eignet sich diese Methode, um die Vorhersage einzelner Datenpunkte zu erklären.
Konzept
Die Vorhersage muss vom Nutzer ausgewählt werden. Besagt z. B. ein Diagnosetool, dass ein Patient wahrscheinlich Krebs hat, würde man Counterfactuals erzeugen für die gegensätzliche Klassifikation “kein Krebs”. Eine Counterfactual-Erklärung könnte sein: Falls ein bestimmter Blutwert kleiner wäre, dann wäre die Diagnose “gesund” gewesen.
Es gibt verschiedene Algorithmen, um Counterfactual-Erklärungen zu finden. Theoretisch kann aber auch ein Mensch Counterfactuals erzeugen, indem er z. B. mit den Eingaben in einem KI-Tool “spielt” und versucht, die Ausgabe zu verändern. Counterfactual Explanations sind somit auch für Laien leichter verständlich. Allerdings ist es immer möglich, beliebig viele Counterfactual-Erklärungen für eine Modellvorhersage zu erstellen.
Beispiel
Kreditwürdigkeit: Eine Person mit bestimmten Attributen (Alter, Geschlecht, Job, Wohnung, Erspartes) beantragt einen Kredit in einer bestimmten Höhe, mit einer bestimmten Dauer und aus einem bestimmten Grund.

Das Modell berechnet die Wahrscheinlichkeit, dass der Kredit zurückgezahlt wird. Die Person hat danach nur eine 24-prozentige Wahrscheinlichkeit, den Kredit zurückzuzahlen. Was müsste anders sein, damit diese Wahrscheinlichkeit bei mindestens 50 % liegt? Hier sind zwei verschiedene Counterfactuals:
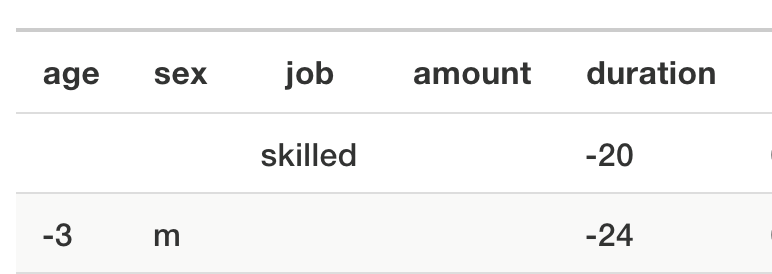
Wäre die Kundin in einem “skilled job“ und die Kreditdauer 20 Monate kürzer, so wäre die Kreditwürdigkeit höher. Wäre die Person ein drei Jahre jüngerer Mann und die Kreditdauer 24 Monate kürzer, hätte sie den Kredit auch erhalten. Auch bei einem „unskilled job“. Es zeigt sich, dass dieser Algorithmus Frauen diskriminiert.
e) Saliency Maps: LRP, GradCAM, Integrated Gradient und Co
Saliency Maps markieren Regionen in Bildern, die wichtig für die Vorhersage von Bilderkennungsalgorithmen basierend auf Deep Learning waren.
Konzept
Saliency Maps sind sehr nützlich, um zu verstehen, warum das Modell das Falsche gelernt hat. Speziell aus der Medizin gibt es viele Beispiele, in denen man erkennen konnte, dass das Modell “Abkürzungen” gelernt hat, die aber nicht hilfreich sind. Diese Fehler waren aber nicht an der Performanz des Modells zu erkennen.
Beispiel
Analyse von Bildern, die zur Hautkrebs-Vorsorge aufgenommen wurden
Durch Saliency Maps lässt sich erkennen, dass ein Neural Network sich auf Markierungen stützt, die das medizinische Personal im Bild gemacht hat, um Melanome zu klassifizieren (Abbildung 5). Das ist natürlich unerwünscht, denn hier fließt bereits indirekt eine Beurteilung ein. Verdächtige Stellen werden eher markiert und vermessen als unverdächtige.
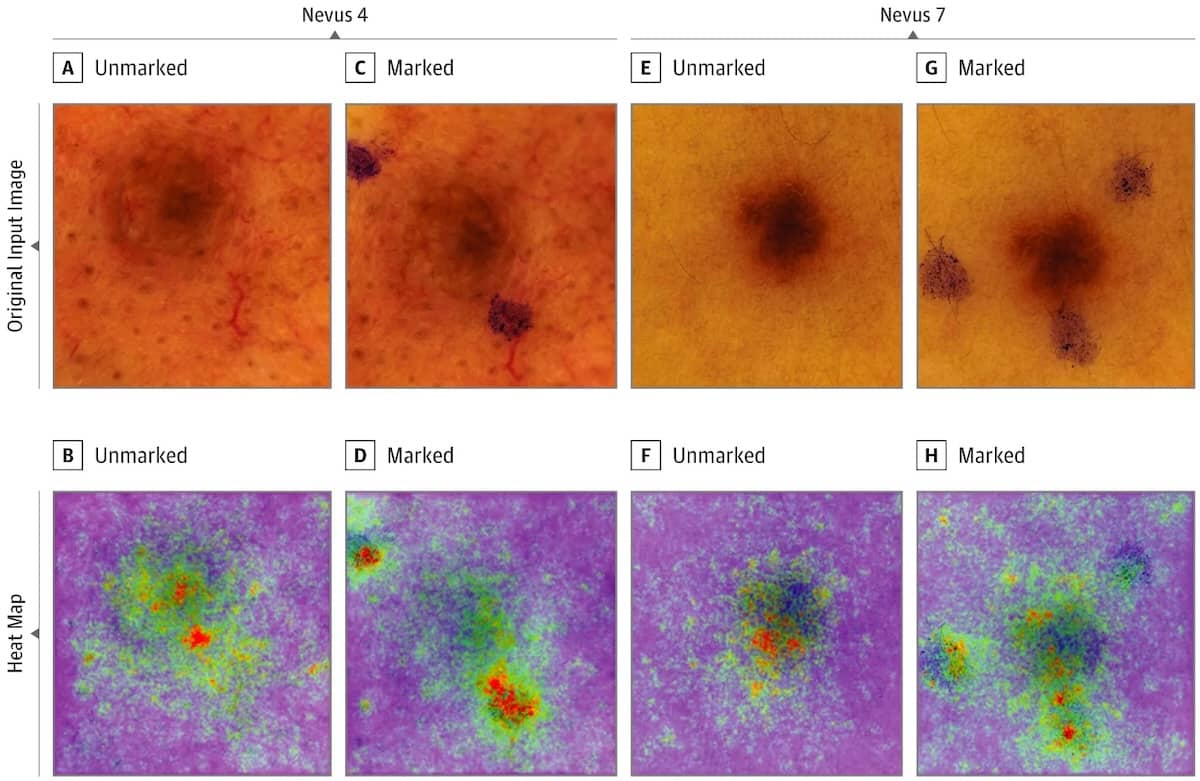
Saliency Maps sind sehr nützlich, um Fehler zu erkennen. Dies gilt vor allem während des Entwicklungsprozesses. Es gibt sehr viele Methoden in dieser Kategorie, z. B. LRP, GradCAM, Vanilla Gradient, Integrated Gradient, DeepLift, DeepTaylor etc. Die Methoden haben gemein, dass sie den Gradienten (die mathematische Ableitung) der Modellvorhersage bezüglich der Input-Pixel nutzen. Einfacher gesagt: Man misst, wie sensitiv die Modellvorhersage bezüglich der Änderungen an den Pixeln ist. Je höher, desto wichtiger der Pixel. Manche Methoden unterscheiden, ob eine Änderung der Pixelintensität die Vorhersage negativ oder positiv verschiebt. Dabei sind Saliency Maps selbst wiederum Bilder, die über die zu klassifizierenden Bilder gelegt werden, um die für die Vorhersage wichtigen Stellen zu markieren.
f) Weitere Methoden speziell für Deep Learning
- Adversarial Attacks
Das sind spezielle Datensätze, die Modelle zu einer Fehlklassifikation verleiten. Zum Beispiel kann man an Bildern leichte Änderungen an den Pixeln vornehmen. Das Bild sieht für einen Menschen normal aus, z. B. sieht man einen Hund darauf. Aber die Klassifikation ist dann schlicht falsch. - Influential Instances
Mithilfe dieser Technik werden die Trainingsdatensätze identifiziert, die für die Klassifikation oder Vorhersage des neuronalen Netzwerks am wichtigsten waren.
Insgesamt bietet dieser Artikel nur einen ersten Einblick in und über die verfügbaren Techniken. Die Vielfalt ist noch viel größer und erst die Zeit wird zeigen, was sich als Standard herausstellt.
5. Regulatorische Betrachtung
Das europäische Medizinprodukterecht stellt keine spezifischen Anforderungen an die Anwendung der künstlichen Intelligenz oder gar die Interpretierbarkeit von Modellen. Allerdings verpflichtet das Medizinprodukterecht die Hersteller zu Folgendem:
- Entwicklung nach Stand der Technik
- Bestmögliches Nutzen-Risiko-Verhältnis
- Sicherheit der Produkte
- Wiederholbarkeit der Ergebnisse
Die oben vorgestellten Methoden entsprechen dem Stand der Technik. Sie tragen dazu bei, Gefährdungen zu entdecken und damit das Risiko zu minimieren und das Risiko-Nutzen-Verhältnis zu verbessern.
Daraus leitet sich ab: ML-basierte Medizinprodukte, die die Methoden zur Interpretierbarkeit ignorieren, entsprechen also nicht dem Stand der Technik. Das gilt zumindest für die Medizinprodukte, deren ML-Modelle einen Einfluss auf die Sicherheit, die Leistungsfähigkeit und den klinischen Nutzen haben.
6. Fazit
Maschinelles Lernen hat aufgrund der hohen Leistungsfähigkeit Einzug in die MedTech-Branche gehalten. Das gilt vor allem für die Bild- und Texterkennung. Die FDA und die europäischen Behörden haben derartige Systeme bereits zugelassen.
Es ist zu erwarten, dass die MedTech-Branche künftig immer häufiger auf maschinelles Lernen setzen wird. Doch genau das kann auch zu Problemen führen: KI, deren Modelle nicht mehr nachzuvollziehen sind, kann für Patientinnen und Patienten gefährlich werden. Möglichen Problemen sollten Hersteller frühzeitig entgegenwirken. Hierbei können unter anderem die Methoden der Interpretierbarkeit helfen.
Interpretierbarkeit ist während der Entwicklungsphase genauso nützlich wie bei der Post-Market Surveillance. Bei dieser sollten die Hersteller genau darauf achten, wie gut die Methode funktioniert – und ob Endanwender die Erklärung auch verstehen können.
7. Weiterführende Ressourcen
- KI-Leitfaden des Johner Instituts
- Blog: Regulatorische Anforderungen an Medizinprodukte mit Machine Learning
- Blog: Validierung von Machine Learning Libraries
- Blog: Künstliche Intelligenz in der Medizin
- Lerneinheiten „Künstliche Intelligenz“ im Auditgarant
- Seminar KI-Anwendungen gesetzeskonform entwickeln
- Buch: Interpretable Machine Learning
Dieser Beitrag wurde initial von Christoph Molnar, Experte für Interpretierbarkeit im maschinellen Lernen, verfasst. Sein Buch Interpretable Machine Learning steht auf seiner Website zur Verfügung.
Das Johner Institut hilft Ihnen gerne dabei, Ihre KI-Medizinprodukte rasch in den Markt zu bekommen und dabei deren Sicherheit und Nutzen zu gewährleisten. Wie genau, erfahren Sie in einem kostenlosen Expertengespräch.