
Das Transfer Learning ist ein spezieller Ansatz beim Machine Learning. Damit bezeichnet man die Wiederverwendung eines vortrainierten Modells (pre-trained model) für ein neues Problem.
Diese Wiederverwendung kann mehr als nur redundante Trainingsarbeit ersparen. Sie bedingt aber, dass Hersteller sich auf neue Fragen von Auditoren und Prüfern einstellen müssen.
1. Transfer Learning: Um was es geht
a) Deep Neural Networks
Das Transfer Learning kommt v.a. bei Deep Neural Networks (DNN) zum Einsatz. Diese Netzwerke bestehen oft aus Hunderten Schichten, die selbst wiederum Hunderte oder Tausende von Neuronen enthalten. Das führt dazu, dass beim Training dieser Netzwerke Millionen Parameter (z.B. Gewichte und Schwellwerte) bestimmt werden müssen.
Die Schichten (Layer) sind nach dem Training in der Lage, unterschiedliche Aufgaben zu übernehmen: So erkennen bei DNN, die mit Bildern trainiert werden, die vorderen Schichten einfache Geometrien wie Kanten. Höhere Schichten können zunehmend komplexere Strukturen detektieren. Die letzte Schicht, der Output Layer, dient typischerweise der Klassifizierung. Er gibt die Wahrscheinlichkeit an, dass ein Input in eine bestimmte Klasse fällt, z.B. ein Bild einen bestimmten Gegenstand anzeigt (s. Abb. 1).
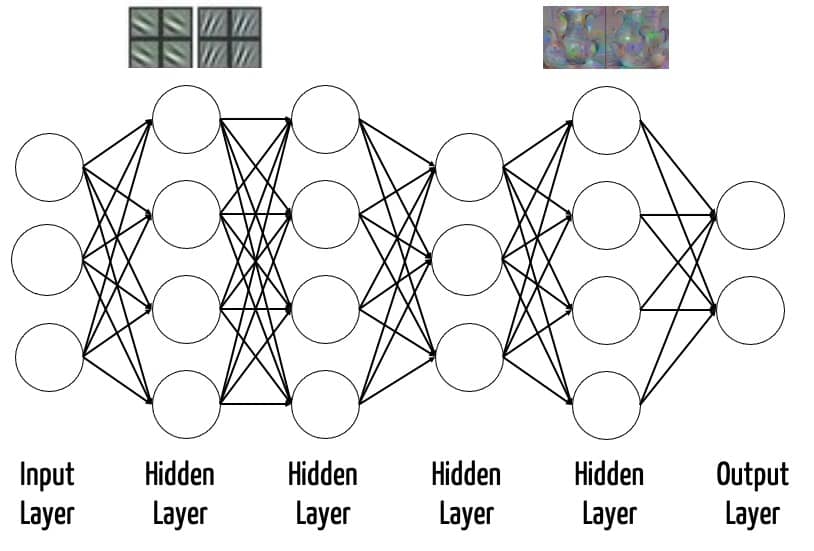
In der medizinischen Diagnostik würde diese letzte Schicht verschiedene Bilder klassifizieren, diese z.B. in maligne und benigne Veränderungen unterteilen oder die Wahrscheinlichkeit eines Schlaganfalls bzw. einer Krebserkrankung bestimmen.
Lesen Sie hier mehr zur Künstlichen Intelligenz und zum Machine Learning bei Medizinprodukten.
b) Transfer Learning durch Pre-Trained Models
Die unteren Schichten sind meist nicht sehr spezifisch für die jeweilige Domäne: In der Bilderkennung bedarf es fast immer der Erkennung einfacher geometrischer Strukturen. Daher bietet es sich an, einen Teil dieser bereits trainierten Schichten wiederzuverwenden und die anderen Schichten mit Input-Daten aus der spezifischen Domäne „nachzutrainieren“.
Die Übernahme von vortrainierten Modellen aus einer Domäne in eine andere nennt man Transfer Learning.
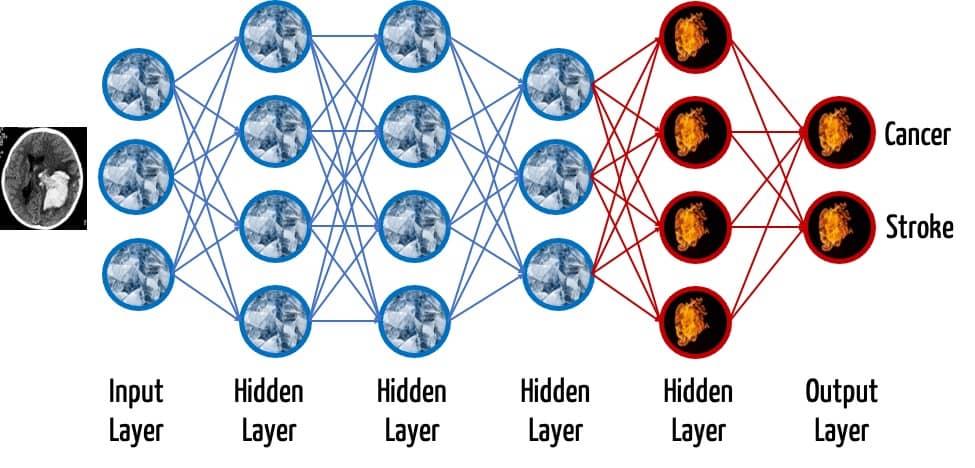
Die letzte Schicht, der Output Layer, wird immer entfernt. Denn die Klassifizierung ist höchst spezifisch für den jeweiligen Anwendungsfall. Wenn beispielsweise ein Modell zwei verschiedene Erkrankungen unterscheiden können soll, dann muss der Output Layer aus zwei Neuronen bestehen.
Wie viele Layer man nachtrainiert und wie viele man unverändert übernimmt, hängt von der Größe des Datensatzes und der Ähnlichkeit der Input-Daten zwischen den Domänen ab.
Weitere Informationen dazu finden Sie hier: Transfer learning from pre-trained models
2. Vorteile des Einsatzes von Pre-Trained Models
Ein Modell zu trainieren, insbesondere ein DNN mit vielen Gewichten, ist ein aufwendiges Unterfangen:
- Trainingsdaten müssen gefunden werden. Eine mögliche Quelle wäre z.B. die Bilddatenbank ImageNet, bei der über die Jahre über 14 Millionen Bilder gesammelt wurden.
- Diese Bilder müssen im nächsten Schritte mit einem Label versehen werden. Es muss also jemand „von Hand“ festlegen, was auf den Bildern zu sehen ist. Das ist bei 14 Millionen Bildern ein arbeitsintensiver Schritt.
- Anschließend müssen das beste Machine-Learning-Verfahren gefunden werden und die beste Architektur dafür.
- Schließlich gilt es noch weitere sogenannte Hyperparameter auszuprobieren.
Die beiden letzten Schritte erfordern ein ressourcenintensives Training der Modelle und eine entsprechende leistungsstarke und stromhungrige Hardware. Die Trainingsprozesse dauern oft Tage und Wochen.
Die Aufwände für diese Arbeitsschritte lassen sich durch das Transfer Learning, d.h. durch die Nutzung von vortrainierten Modellen, verringern.
Doch nicht nur die Effizienz des Lernens ist ein Vorteil: Oft stehen gar nicht genügend Trainingsdaten bereit, weshalb ein Hersteller, der bei null beginnt, gar nicht die Leistungsfähigkeit (z.B. Sensitivität) eines vortrainierten Modells erreichen kann.
3. Risiken beim Transfer Learning
a) Suboptimales Modell
Das Bemühen jedes Herstellers besteht darin, ein möglichst leistungsfähiges Modell zu entwickeln. Dazu muss er verschiedene Modelle vergleichen. Dem Hersteller bleibt also keine andere Wahl, als diese Modelle auszuprobieren: sie zu entwickeln, zu trainieren und zu bewerten. Genau dieser Vergleich ist aufwendig.
Zudem sind vortrainierte Modelle nicht generell besser. Oft gelingt es, durch kleinere, spezialisierte und speziell trainierte Netzwerke zumindest vergleichbar gute, manchmal sogar bessere Ergebnisse zu erzielen.
Wie hoch der Nutzen ist, hängt von der Ähnlichkeit der eigenen Daten mit dem Datensatz ab, mit dem das Modell vortrainiert wurde. Da radiologische Bilder sich von den Bildern auf z.B. ImageNet stark unterscheiden (z.B. in Inhalt und Farbgebung), bleibt den Herstellern oft nur der Trial-and-Error-Ansatz, um das beste Modell zu finden.
b) Kompromittierung des Datenschutzes
Unter gewissen Umständen gelingt es seIbst bei großen Modellen, Informationen aus den Trainingsdaten zu extrahieren.
Bei medizinischen Daten ist es aber besonders unerwünscht, dass aus dem Output des Modells Rückschlüsse auf die Trainingsdaten und damit auf Gesundheitsdaten individueller Patienten gezogen werden könnten. Dabei muss ein „Angreifer“ nicht einmal Zugang zum Innenleben des Modells haben, wie eine Studie von Google und mehrere US-Universitäten zeigte.
c) Kompromittierung der Datensicherheit
Ein Angriff kann auch den Trainingsdaten gelten. In dieser Publikation eines Forscherteams der Universität Chicago wurde nachgewiesen, wie sich die Trainingsdaten (hier Bilder) eines vortrainierten Modells unsichtbar so modifizieren lassen, dass sie später zu falschen Klassifizierungen führen.
Bei einem Datensatz aus Texten gelang es, eine back door in die Trainingsdaten einzubauen. Diese Hintertür führte dazu, dass das Modell einen Input-Text bei Vorhandensein eines vom Angreifer bestimmten Schlüsselworts in einer von ihm gewünschten Weise klassifizierte – unabhängig vom restlichen Text, der sonst anders klassifiziert worden wäre.
Wenn Modelle anhand öffentlich verfügbarer Daten vortrainiert werden, stellen solche Angriffe ein größeres Risiko dar, als wenn Modelle mit Daten trainiert werden, die ein Hersteller ausschließlich unter der eigenen Kontrolle hat.
d) Sonstige Risiken
Vortrainierte Modelle können den gleichen Schwächen unterliegen wie selbst trainierte Modelle, z.B.:
- Falsche Vorhersagen aufgrund von Overfitting
- Falsche Vorhersagen für bestimmte Input-Daten aufgrund eines Bias des Modells
- Nur zufällig richtige Vorhersagen
- u.v.m.
4. Regulatorische Bewertung des Transfer Learnings
a) Modell = Software?
Ein vortrainiertes Modell besteht aus einer Modellarchitektur und aus den gefitteten Werten (z.B. Gewichten, Schwellwerten). Standards wie ONNX ermöglichen den Modellaustausch sogar zwischen verschiedenen Bibliotheken wie PyTourch, Tensorflow oder das darauf aufbauende Kerras.
Doch entspricht so ein Modell nicht eher Daten?
Die MDCG definiert Software wie folgt:
Damit wäre das Modell selbst nicht als Software zu verstehen. Andere Definitionen sehen das jedoch anders:
Da es für das Ergebnis unerheblich ist, ob der Hersteller das Modell durch explizite Instruktionen oder durch eine Kombination von parametrisierten Instruktionen und diesen Parametern erzeugt, kann man das Modell und die zugehörige ausführende Bibliothek als Software zu betrachten.
b) Modell = SOUP?
Damit liegt es auf der Hand, dass die Machine Learning Library (zumindest der Teil, der mithilfe des Modells die Vorhersage macht) sowie der unverändert übernommene Teil des Modells als SOUP (Software of Unknown Provenance) zu betrachten sind, da diese Teil des Medizinprodukts werden.
Dabei entsteht die Schwierigkeit, dass das Modell und seine Daten als SOUP zwar eine Software-Komponente bilden; doch die Schnittstellen dieser Komponenten sind kaum zu spezifizieren noch isoliert testbar.

c) Dokumentation
In der Beratungspraxis beobachtet das Johner Institut, dass Hersteller vortrainierte Modelle verwenden, ohne das zu thematisieren, manchmal sogar ohne diese zu validieren. Beides stellt einen Verstoß gegen die Vorgaben der IEC 62304 dar und entzieht einem fundierten Risikomanagement die Grundlage.
d) Risikomanagement
Transfer Learning hilft den Herstellern, die Entwicklung und das Trainieren von ML-basierten Modellen zu beschleunigen. Allerdings ergeben sich daraus spezifische Anforderungen aus dem Risikomanagement:
- Um das Nutzen-Risiko-Verhältnis zu optimieren, sind Hersteller gehalten, verschiedene Varianten zu evaluieren. Diese „Verschiedenheit“ bezieht sich auf:
- Varianten mit und ohne vortrainiertem Modell
- Die Größe des Anteils der vortrainierten Bereiche, die der Hersteller entfernt und neu trainiert
- Entscheidung, ob er bereits trainierte Bereiche „nachtrainiert“ (d.h., ob bereits trainierte Gewichte frozen sind oder nicht)
- Die Risiken durch das Transfer Learning müssen die Hersteller identifizieren und beherrschen. Dazu zählen die bereits oben genannten Risiken:
- Kompromittierung der Datensicherheit durch Angriffe auf die Trainingsdaten und damit die Modellparameter
- Suboptimale Ergebnisse aufgrund eines Bias in den Daten des vortrainierten Modells
- Fehlklassifizierungen bei unerwarteten Input-Daten oder Input-Daten, die zufällig in den vortrainierten Schichten als Feature (miss)interpretiert werden
- Fehlklassifizierungen aufgrund von fehlerhaftem Labeling der Trainingsdaten des vortrainierten Modells
e) CSV
Eine Schwierigkeit aller ML-Bibliotheken bleibt bestehen: Unterschiedlichen Regularien bestimmen, wie unterschiedliche Teile einer Library zu betrachten sind:
- Ein Teil fällt unter den Anwendungsbereich der ISO 13485 und muss daher den Anforderungen zur Validierung computerisierter Systeme genügen.
- Ein zweiter Teil muss die Anforderungen der IEC 62304 erfüllen.
Diese Aufteilung erfolgt anhand der Funktionalität.
Lesen Sie mehr zu diesem Thema im Artikel zur Validierung von ML-Bibliotheken.
5. Fazit
Transfer Learning gewinnt an Popularität. Das ist auch der Tatsache geschuldet, dass mit vortrainierten Modellen sehr schnell vergleichbar gute Ergebnisse zu erzielen sind.
Doch für Medizinproduktehersteller liegen die Anforderungen sehr hoch: Ein „gut genug“ reicht nicht aus. Vielmehr müssen die Hersteller nachvollziehbar argumentieren, dass das von ihnen gewählte Vorgehen zur besten Leistungsfähigkeit und damit zum besten Nutzen-Risiko-Verhältnis führt.
Bei einigen Anwendungsfällen ist zu vermuten, dass das Transfer Learning zu den besten Ergebnissen führt, weil es auf möglichst großen Trainingsdatensätzen beruht. Dazu zählt beispielsweise das Finetuning eines Modells für die leicht unterschiedlichen Bilddaten, welche die bildgebenden Modalitäten (z.B. CT, MRT) verschiedener Hersteller liefern.
Die Anforderungen an das technische Verständnis der Auditoren und die Kenntnis der Hersteller bezüglich des aktuellen Stands der Technik steigen weiterhin. Der Leitfaden des Johner Instituts, den die Benannten Stellen in abgewandelter Form nutzen, kann beiden Seiten helfen, zu einem gemeinsamen Verständnis (der Anforderungen) zu gelangen.
Mit diesem Hilfsmittel sind die regulatorischen Risiken beherrschbar. Hersteller sollten die Möglichkeiten des Transfer Learnings ausprobieren, um mit einer höheren Wahrscheinlichkeit das für den konkreten Anwendungsfall sicherste und leistungsfähigste Modell entwickeln zu können.
Wir empfehlen Ihnen den Podcast zu diesem Thema. Erleben Sie Prof. Oliver Haase und Prof. Christian Johner im Gespräch.
Das Johner Institut unterstützt Medizinproduktehersteller beim gesetzeskonformen Einsatz von Methoden des Maschine Learnings. Nehmen Sie gerne Kontakt auf.


